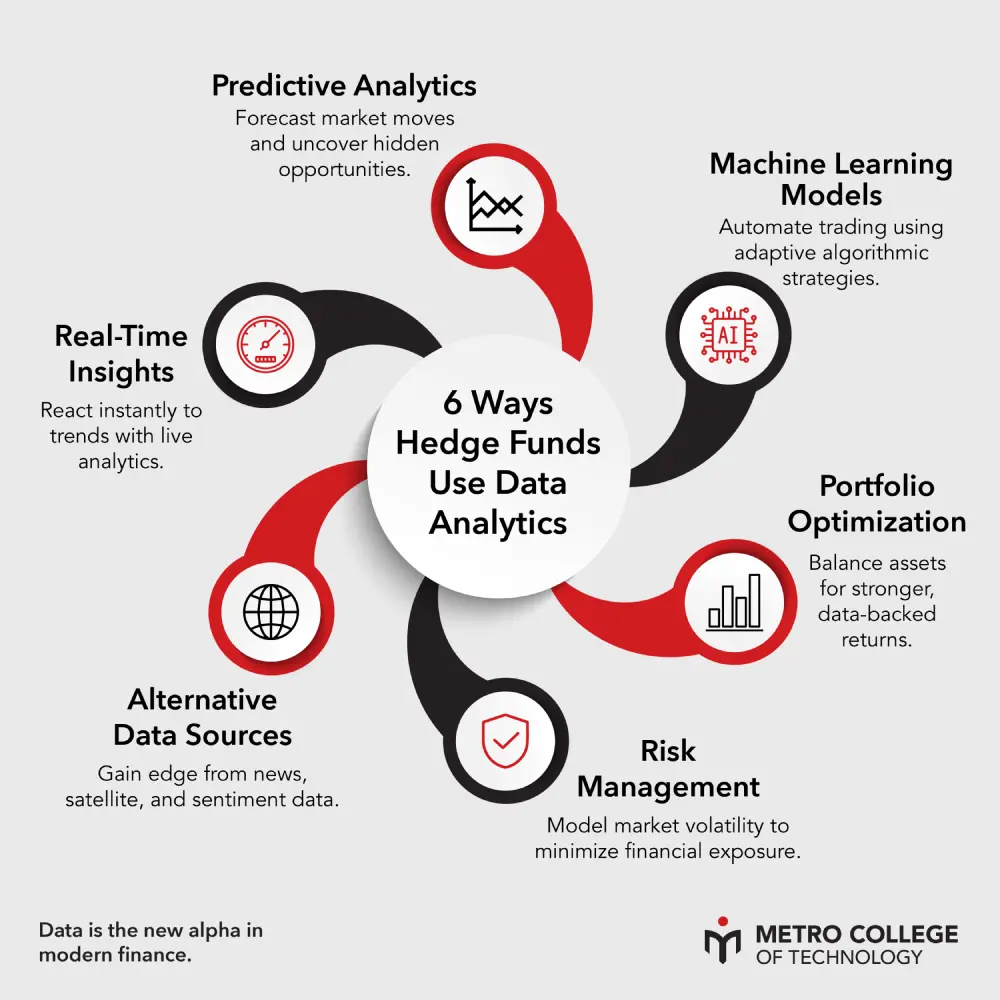
Advanced statistical modeling and machine learning methods share one goal: finding patterns in data to make predictions. Yet they approach that goal through different philosophies, techniques, and mindsets. Statistical modeling is rooted in inference, explaining why outcomes occur, while machine learning is built for prediction, focusing on what will happen next. Understanding these distinctions is essential for any professional aiming to use data to make decisions, forecast results, or drive business strategy.
Key Takeaways
- Statistical modeling explains relationships in data using formal assumptions, while machine learning prioritizes accurate prediction through adaptable algorithms.
- You need both skills in modern analytics, statistical inference for validation, and machine learning for scale and automation.
- Combining them allows organizations to balance interpretability, accuracy, and efficiency in real-world decision-making.
Connecting Two Worlds: Statistical Modeling and Machine Learning in Practice
In today’s analytics-driven economy, the line between is fading. A marketing analyst uses regression to predict conversions; a financial institution trains a neural network to detect fraud; a healthcare researcher tests statistical significance for treatment effects. Each draws from the same data foundation, but their tools differ in flexibility, interpretability, and scalability.
When machine learning offers better returns, and how hybrid approaches can amplify your predictive capabilities. Even if you’re managing data teams or preparing to upskill with Python for Data Analytics training in Toronto, understanding these distinctions gives you an edge.
Fundamental Differences Between Statistical Modeling and Machine Learning
Statistical modeling has existed for more than a century, built on probability theory and the need to explain cause-and-effect relationships. Machine learning, born from computer science, focuses on designing systems that automatically learn from data to improve performance.
Statistical modeling depends on assumptions, normal distributions, independence, and linearity to infer population characteristics. You interpret coefficients, check p-values, and test hypotheses. The output is human-readable and mathematically interpretable.
Machine learning, in contrast, minimizes human intervention. Instead of predefined equations, it learns patterns from raw data, using algorithms like random forests and neural networks. The goal isn’t to explain why something happens but to forecast what happens next with minimal error.
Here’s how they differ in key areas:
| Aspect | Advanced Statistical Modeling | Machine Learning Methods |
| Purpose | Explain relationships, test hypotheses | Predict outcomes accurately |
| Approach | Based on assumptions, uses smaller structured data | Data-driven, handles large unstructured data |
| Interpretability | High – model parameters are clear | Often low – models act like black boxes |
| Computation | Moderate | High – requires greater processing power |
| Accuracy with Big Data | Limited scalability | High adaptability with complex datasets |
| Typical Tools | SAS, R, SQL, regression methods | Python, TensorFlow, scikit-learn, deep learning |
Both approaches serve distinct business purposes. For example, if your goal is to validate the relationship between advertising spend and sales growth, advanced statistical modeling gives you clarity and control. If your goal is to predict next quarter’s sales across hundreds of variables, machine learning offers speed and adaptability.
When to Use Advanced Statistical Modeling vs Machine Learning Algorithms
Choosing between these methods depends on your data, goal, and business context. In most real-world projects, you’ll use both, not as rivals, but as complementary tools.
Use advanced statistical modeling when the purpose is explanation. Suppose you’re in finance, evaluating which factors influence credit risk. Regression analysis can help quantify the impact of income, debt ratio, and repayment history. The objective is to understand the weight of each variable, not only to predict defaults.
On the other hand, machine learning is suited for pattern recognition where relationships are non-linear or unknown. If you’re working in retail and need to forecast demand for thousands of products, machine learning models can adapt to new data streams in real time, producing more accurate predictions than static regression models.
In business analytics, both coexist:
- Statistical models justify decisions for compliance and stakeholder reporting.
- Machine learning drives automation, personalization, and anomaly detection.
For professionals aiming to advance their careers, learning both disciplines through hands-on programs like Machine Learning & Big Data Analytics builds an adaptable skill set that translates directly into demand across finance, marketing, and technology industries.

Master Both Worlds: From Regression to Neural Networks
Gain practical experience in Python, SQL, and machine learning techniques that employers value. Start learning how to design predictive models that perform in real business environments.
Start Learning TodayKey Assumptions and Limitations of Statistical Models
Every statistical model carries assumptions, and when those assumptions break, so does accuracy. Understanding these is crucial before applying advanced statistical modeling in practice.
- Linearity: Many models assume a straight-line relationship between predictors and outcomes. When this fails, non-linear models or transformations are needed.
- Normality: Data distributions are expected to follow normal patterns. Skewed or heavy-tailed data can distort results.
- Independence: Observations should not influence one another. Violations occur in time-series or grouped data.
- Homoscedasticity: The variance of errors should remain constant across observations. Uneven variance affects confidence intervals.
- No Multicollinearity: Predictors should not be too correlated. Otherwise, the model struggles to assign accurate weights.
Statistical models also face practical limitations. They depend heavily on data quality and require smaller, cleaner, well-defined datasets. Unlike machine learning, they can’t easily scale to millions of records without simplifying assumptions. That’s why professionals skilled in SQL and data preprocessing techniques from programs like Network Administration – MCSA often outperform peers who rely solely on plug-and-play analytics tools.
Flexibility and Scalability of Machine Learning Methods with Big Data
Machine learning thrives in environments where data volume, velocity, and variety overwhelm traditional models. Unlike classical statistical techniques, ML systems can analyze images, text, and streaming data simultaneously.
This flexibility comes from algorithmic design. Methods such as gradient boosting or convolutional neural networks don’t assume specific relationships between variables; they learn directly from data. That independence enables them to identify complex non-linear patterns across massive datasets.
Scalability also sets machine learning apart. Cloud platforms and distributed frameworks allow models to train on billions of records efficiently. While statistical modeling depends on sample-based inference, machine learning expands through computational power. For companies managing global data pipelines, this scalability means faster predictions and higher ROI.
A common misconception is that machine learning eliminates the need for domain expertise. In reality, your understanding of business context, feature engineering, and data ethics shapes how algorithms behave. That’s why professionals trained in data analytics tools like Tableau and Python remain critical to successful deployment.
Interpretability vs Predictive Accuracy: Trade-offs Between Both Approaches
One of the most debated questions in analytics: do you prefer clarity or precision? Statistical models are transparent; you can interpret each coefficient, test significance, and explain relationships. Machine learning models, especially deep learning, often achieve higher accuracy at the cost of interpretability.
This trade-off matters in industries where accountability is mandatory. Financial regulators, for instance, demand explainable models to justify lending decisions. Healthcare providers must interpret model outcomes before applying them to patients. Machine learning might outperform statistically, yet decision-makers rely on the interpretability that statistical modeling provides.
The balance depends on purpose. For research and reporting, transparency wins. For commercial optimization, think real-time ad targeting; accuracy takes priority. Here’s how both compare:
| Aspect | Statistical Modeling | Machine Learning |
| Interpretability | Clear equations, coefficients, and assumptions | Limited transparency, especially in deep models |
| Accuracy | Moderate for small data | High for large, complex datasets |
| Use Case Fit | Ideal for analysis and validation | Best for automation and prediction |
| Decision Support | Strong for explaining “why” | Strong for predicting “what next” |
Many organizations now adopt explainable AI (XAI) frameworks to merge these benefits, using interpretable layers to describe the behavior of complex ML models.
Role of Statistical Inference and Hypothesis Testing in Predictive Modeling
Statistical inference builds the bridge between data and decision-making. While machine learning emphasizes prediction, inference ensures that those predictions stand on solid ground.
In advanced statistical modeling, inference techniques help validate findings, ensuring models generalize beyond specific datasets. Hypothesis testing determines whether observed effects are statistically meaningful or random. In predictive analytics, these concepts maintain rigor and reliability.
- p-Values: Quantify evidence against the null hypothesis. Low p-values suggest genuine effects worth exploring.
- Confidence Intervals: Provide a range of probable values for estimated parameters.
- Significance Testing: Helps identify which features truly influence outcomes, refining model structure.
Combining inference with predictive algorithms ensures that models not only perform but also explain results with confidence, a critical advantage for analysts using Data Science (SAS + Python) who manage high-stakes business analytics.
Common Algorithms in Statistical Modeling (Regression, ANOVA) vs Machine Learning (Random Forest, Neural Networks)
Each method has a toolkit that defines its strength. Statistical models revolve around interpretability, while machine learning algorithms focus on adaptability.
Common Statistical Modeling Techniques
- Linear Regression: Estimates relationships between dependent and independent variables using least squares.
- Logistic Regression: Predicts categorical outcomes, widely used in risk analysis and marketing segmentation.
- ANOVA (Analysis of Variance): Compares means across groups to identify significant differences.
Common Machine Learning Algorithms
- Random Forest: An ensemble of decision trees improving accuracy through averaged predictions.
- Support Vector Machines: Finds optimal boundaries for classification and regression problems.
- Neural Networks: Mimic brain architecture to detect patterns in text, images, and signals.
Learning these algorithms across platforms like Python, SAS, and SQL gives you flexibility. Modern data professionals integrate techniques seamlessly, often building hybrid systems for both interpretation and prediction.

Data Requirements and Preprocessing for Both Techniques
Every model’s performance depends on data quality. Advanced statistical modeling demands clean, well-structured datasets with defined variables and controlled sampling. Machine learning can process raw or semi-structured data, yet still requires thoughtful preprocessing.
Statistical Modeling Data Needs
- Structured Data: Clearly defined rows and columns.
- Data Validation: Outlier detection and normalization required.
- Feature Selection: Variables must align with theoretical assumptions.
Machine Learning Data Needs
- Large Datasets: More samples yield better training performance.
- Feature Engineering: Transform raw inputs into meaningful representations.
- Imputation: Handles missing or corrupted values automatically.
For professionals working toward advanced analytics roles, mastering preprocessing through Python for Data Analytics and Network Administration – MCSA offers important foundations.
Hybrid Approaches Combining Statistical Models and Machine Learning
Many real-world problems demand both interpretability and accuracy. Hybrid models bridge that gap by integrating statistical rigor with machine learning flexibility.
For example, businesses may use regression models for feature selection and then feed those features into an ensemble machine learning model for prediction. Others build “stacked models,” combining logistic regression outputs with neural networks to enhance precision while retaining interpretability.
Hybrid approaches are also useful in production systems. E-commerce platforms may start with statistical models to understand customer segments, then apply machine learning algorithms for recommendation systems. The synergy allows companies to test hypotheses, forecast outcomes, and automate decisions in one unified framework.
This integration also aligns with industry hiring trends. Employers value professionals who can interpret models, validate assumptions, and deploy them in Python or Tableau environments, bridging analytics and automation seamlessly.
FAQ
Is advanced statistical modeling still relevant in the era of AI?
Absolutely. Statistical modeling remains the foundation of quantitative reasoning. Machine learning builds upon its concepts, not replaces them.
Which is easier to learn for beginners?
Statistical modeling offers a gentler entry, focusing on logic and assumptions. Machine learning demands coding skills and computational understanding.
Do I need programming skills to perform statistical modeling?
Basic programming in Python or SAS enhances your efficiency, especially when handling large datasets.
Can I combine statistical modeling and machine learning in one project?
Yes. Many analysts build hybrid systems that use statistical inference to refine inputs for machine learning predictions.
Which tools should I learn to master both methods?
Start with Python for analytics, move to SAS for enterprise reporting, and explore Tableau for visualization.
Balancing Interpretability, Accuracy, and Scalability in Predictive Modeling
The most effective data professionals strike a balance between interpretability and accuracy. Advanced statistical modeling provides the language to explain outcomes; machine learning delivers the power to scale predictions. When used together, they elevate decision-making from insight to action.
In a market defined by data velocity and complexity, your competitive edge lies in mastering both. Equip yourself with the analytical foundation of statistics and the adaptability of machine learning. Programs like Metro College’s Python, SAS, SQL, and Tableau training help you apply these methods directly to real business challenges, transforming theory into measurable performance.
With the right skills, you don’t just predict the future. You shape it.

Turn Big Data into Smart Insights
Learn visualization and analytics skills that help interpret machine learning results using interactive dashboards and statistical storytelling.
Explore Analytics Training